Memory Allocation
Managing the device memory in Vulkan is something some developers might be new to and it is important to understand some of the basics.
Two really great Khronos presentations on Vulkan Memory Management from Vulkan Dev Day Montreal (video) and 2018 Vulkanised (video) are great ways to learn some of the main concepts.
It is also worth noting that managing memory is not easy and developers might want to opt instead to use libraries such as Vulkan Memory Allocator to help.
Sub-allocation
Sub-allocation is considered to be a first-class approach when working in Vulkan. It is also important to realize there is a maxMemoryAllocationCount which creates a limit to the number of simultaneously active allocations an application can use at once. Memory allocation and deallocation at the OS/driver level is likely to be really slow which is another reason for sub-allocation. A Vulkan app should aim to create large allocations and then manage them itself.
Transfer
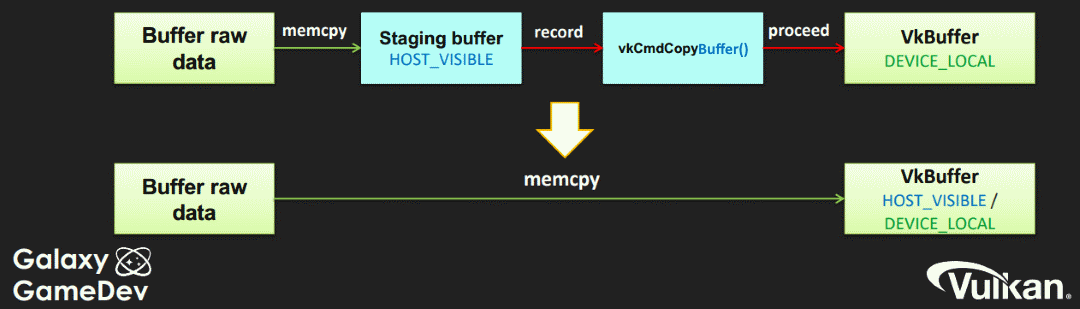
The VkPhysicalDeviceType advertises two main different types of GPUs, discrete and integrated (also referred to as UMA (unified memory architecture)). It is important for performance to understand the difference between the two.
Discrete graphics cards contain their own dedicated memory on the device. The data is transferred over a bus (such as PCIe) which is usually a bottleneck due to the physical speed limitation of transferring data. Some physical devices will advertise a queue with a VK_QUEUE_TRANSFER_BIT which allows for a dedicated queue for transferring data. The common practice is to create a staging buffer to copy the host data into before sending through a command buffer to copy over to the device local memory.
UMA systems share the memory between the device and host which is advertised with a VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT | VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT combination. The disadvantage of this is that system memory has to be shared with the GPU which requires being cautious of memory pressure. The main advantage is that there is no need to create a staging buffer and the transfer overhead is greatly reduced.
Lazily Allocated Memory
On tile-based architectures (virtually all mobile GPUs) the LAZILY_ALLOCATED_BIT memory type is not backed by actual memory. It can be used for attachments that can be held in tile memory, such as the G-buffer between subpasses, depth buffer, or multi-sampled images. This saves some significant bandwidth cost for writing the image back to memory. You can find more information in Khronos' tutorials on Render Passes and Subpasses.