Compute Shader
Introduction
In this bonus chapter, we’ll take a look at compute shaders. Up until now, all previous chapters dealt with the traditional graphics part of the Vulkan pipeline. But unlike older APIs like OpenGL, compute shader support in Vulkan is mandatory. This means that you can use compute shaders on every Vulkan implementation available, no matter if it’s a high-end desktop GPU or a low-powered embedded device.
This opens up the world of general purpose computing on graphics processor units (GPGPU), no matter where your application is running. GPGPU means that you can do general computations on your GPU, something that has traditionally been a domain of CPUs. But with GPUs having become more and more powerful and more flexible, many workloads that would require the general purpose capabilities of a CPU can now be done on the GPU in realtime.
A few examples of where the compute capabilities of a GPU can be used are image manipulation, visibility testing, post-processing, advanced lighting calculations, animations, physics, (e.g., for a particle system) and much more. And it’s even possible to use compute for non-visual computational only work that does not require any graphics output, e.g., number crunching or AI related things. This is called "headless compute".
Advantages
Doing computationally expensive calculations on the GPU has several advantages. The most obvious one is offloading work from the CPU. Another one is not requiring moving data between the CPU’s main memory and the GPU’s memory. All the data can stay on the GPU without having to wait for slow transfers from the main memory.
Aside from these, GPUs are heavily parallelized with some of them having tens of thousands of small compute units. This often makes them a better fit for highly parallel workflows than a CPU with a few large compute units.
The Vulkan pipeline
It’s important to know that compute is completely separated from the graphics part of the pipeline. This is visible in the following block diagram of the Vulkan pipeline from the official specification:
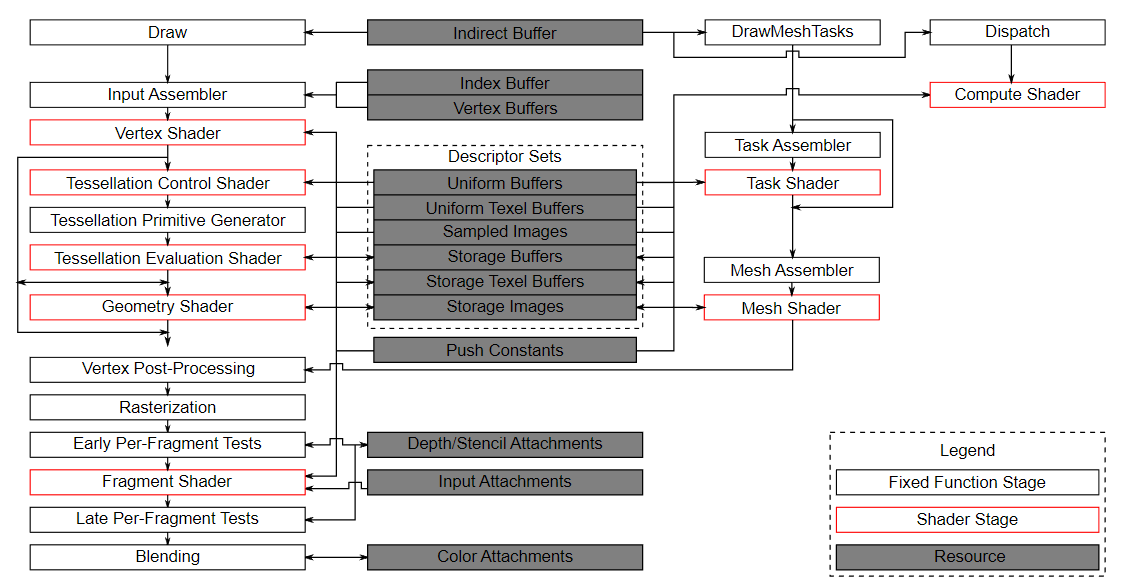
In this diagram we can see the traditional graphics part of the pipeline on the left, and several stages on the right that are not part of this graphics pipeline, including the compute shader (stage). With the compute shader stage being detached from the graphics pipeline, we’ll be able to use it anywhere we see fit. This is very different from e.g., the fragment shader which is always applied to the transformed output of the vertex shader.
The center of the diagram also shows that e.g., descriptor sets are also used by compute, so everything we learned about descriptor layouts, descriptor sets, and descriptors also applies here.
An example
An easy-to-understand example that we will implement in this chapter is a GPU-based particle system. Such systems are used in many games and often consist of thousands of particles that need to be updated at interactive frame rates. Rendering such a system requires two main parts: vertices, passed as vertex buffers, and a way to update them based on some equation.
The "classical" CPU-based particle system would store particle data in the system’s main memory and then use the CPU to update them. After the update, the vertices need to be transferred to the GPU’s memory again so it can display the updated particles in the next frame. The most straight-forward way would be recreating the vertex buffer with the new data for each frame. This is very costly. Depending on your implementation, there are other options like mapping GPU memory so it can be written by the CPU. (Called "resizable BAR" on desktop systems, or unified memory on integrated GPUs) or just using a host local buffer (which would be the slowest method due to PCI-E bandwidth). But no matter what buffer update method you choose, you always require a "round-trip" to the CPU to update the particles.
With a GPU-based particle system, this round-trip is no longer required. Vertices are only uploaded to the GPU at the start, and all updates are done in the GPU’s memory using compute shaders. One of the main reasons why this is faster is the much higher bandwidth between the GPU and its local memory. In a CPU-based scenario, you’d be limited by main memory and PCI-express bandwidth, which is often just a fraction of the GPU’s memory bandwidth.
When doing this on a GPU with a dedicated compute queue, you can update particles in parallel to the rendering part of the graphics pipeline. This is called "async compute", and is an advanced topic not covered in this tutorial.
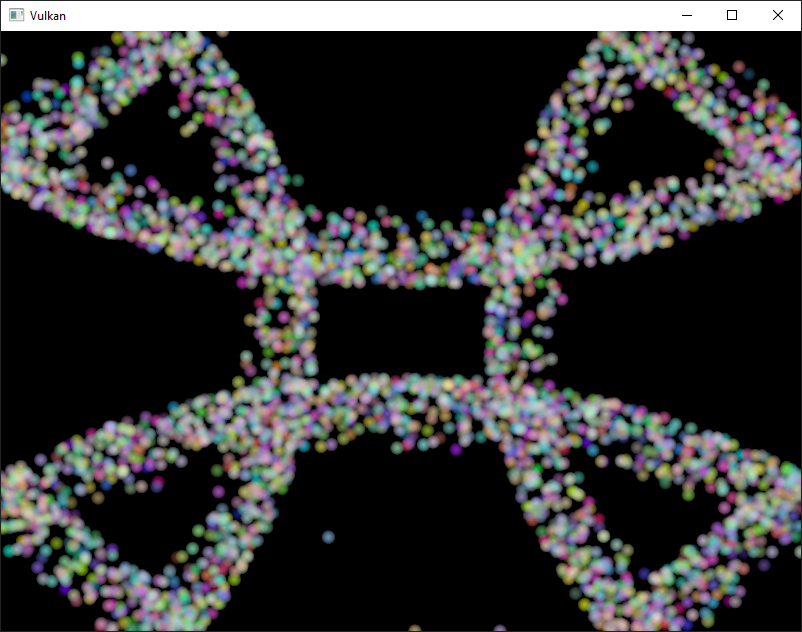
Here is a screenshot from this chapter’s code. The particles shown here are updated by a compute shader directly on the GPU, without any CPU interaction:
Data manipulation
In this tutorial, we have already learned about different buffer types like vertex and index buffers for passing primitives and uniform buffers for passing data to a shader. And we also used images to do texture mapping. But up until now, we always wrote data using the CPU and only did reads on the GPU.
An important concept introduced with compute shaders is the ability to arbitrarily read from and write to buffers. For this, Vulkan offers two dedicated storage types.
Shader storage buffer objects (SSBO)
A shader storage buffer (SSBO) allows shaders to read from and write to a buffer. Using this is similar to using uniform buffer objects. The biggest differences are that you can alias other buffer types to SSBOs and that they can be arbitrarily large.
Going back to the GPU-based particle system, you might now wonder how to deal with vertices being updated (written) by the compute shader and read (drawn) by the vertex shader, as both usages would seemingly require different buffer types.
But that’s not the case. In Vulkan, you can specify multiple usages for buffers and images. So for the particle vertex buffer to be used as a vertex buffer (in the graphics pass) and as a storage buffer (in the compute pass), you simply create the buffer with those two usage flags:
vk::BufferCreateInfo bufferInfo{};
...
bufferInfo.usage = vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eTransferDst;
...
shaderStorageBuffers[i] = vk::raii::Buffer(*device, bufferInfo);The two flags vk::BufferUsageFlagBits::eVertexBuffer and vk::BufferUsageFlagBits::eStorageBuffer set with bufferInfo.usage tell the implementation that we want to use this buffer for two different scenarios: as a vertex buffer in the vertex shader and as a store buffer.
Note that we also added the vk::BufferUsageFlagBits::eTransferDst flag in here so we can transfer data from the host to the GPU.
This is crucial as we want the shader storage buffer to stay in GPU memory only (vk::MemoryPropertyFlagBits::eDeviceLocal) we need to transfer data from the host to this buffer.
Here is the same code using the createBuffer helper function:
vk::raii::Buffer shaderStorageBufferTemp({});
vk::raii::DeviceMemory shaderStorageBufferTempMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eTransferDst, vk::MemoryPropertyFlagBits::eDeviceLocal, shaderStorageBufferTemp, shaderStorageBufferTempMemory);
copyBuffer(stagingBuffer, shaderStorageBufferTemp, bufferSize);
shaderStorageBuffers.emplace_back(std::move(shaderStorageBufferTemp));
shaderStorageBuffersMemory.emplace_back(std::move(shaderStorageBufferTempMemory));The Slang shader declaration for accessing such a buffer looks like this:
struct Particle {
float2 position;
float2 velocity;
float4 color;
};
struct ParticleSSBO {
Particle particles;
};
StructuredBuffer<ParticleSSBO> particlesIn;
RWStructuredBuffer<ParticleSSBO> particlesOut;In this example we have a typed SSBO with each particle having a position and velocity value (see the Particle struct).
The SSBO then contains an unbound number of particles as it is placed into a
StructuredBuffer without upper limit, and it’s a read-only buffer for
particlesIn. For particlesOut, we place it into a RWStructedBuffer.
Not having to specify the number of elements in an SSBO is one of the advantages over e.g.
uniform buffers.
Writing to such a storage buffer object in the compute shader is straight-forward and similar to how you’d write to the buffer on the C++ side:
particlesOut[index].particles.position = particlesIn[index].particles.position + particlesIn[index].particles.velocity.xy * ubo.deltaTime;Storage images
Note that we won’t be doing image manipulation in this chapter. This paragraph is here to make readers aware that compute shaders can also be used for image manipulation.
A storage image allows you to read from and write to an image. Typical use cases are applying image effects to textures, doing post-processing (which in turn is very similar) or generating mip-maps.
This is similar for images:
vk::ImageCreateInfo imageInfo {};
...
imageInfo.usage = vk::ImageUsageFlagBits::eSampled | vk::ImageUsageFlagBits::eStorage;
...
textureImage = std::make_unique<vk::raii::SwapchainKHR>( *device, swapChainCreateInfo );The two flags vk::ImageUsageFlagBits::eSampled and vk::ImageUsageFlagBits::eStorage set with imageInfo.usage tell the implementation that we want to use this image for two different scenarios: as an image sampled in the fragment shader and as a storage image in the computer shader;
The Slang shader declaration for storage image looks similar to sampled images used, e.g., in the fragment shader:
[vk::image_format("r32f")] Texture2D<float> inputImage;
[vk::image_format("r32f")] RWTexture2D<float> outputImage;A few differences here are additional attributes like r32f for the format of
the image, the usage of the read-only Texture2D and read-write RWTexture2D
designations.
And last but not least we need to use the RWTexture2D type to declare a
storage image.
Reading from and writing to storage images in the compute shader is then done array lookup syntax:
float3 pixel = inputImage[int2(gl_GlobalInvocationID.xy)].rgb;
outputImage[int2(gl_GlobalInvocationID.xy)] = pixel;Compute queue families
In the physical device and queue families chapter,
we have already learned about queue families and how to select a graphics queue family.
Compute uses the queue family properties flag bit vk::QueueFlagBits::eCompute.
So if we want to do compute work, we need to get a queue from a queue family that supports compute.
Note that Vulkan requires an implementation which supports graphics operations to have at least one queue family that supports both graphics and compute operations, but it’s also possible that implementations offer a dedicated compute queue. This dedicated compute queue (that does not have the graphics bit) hints at an asynchronous compute queue. To keep this tutorial beginner-friendly though, we’ll use a queue that can do both graphics and compute operations. This will also save us from dealing with several advanced synchronization mechanisms.
For our compute sample, we need to change the device creation code a bit:
std::vector<vk::QueueFamilyProperties> queueFamilyProperties = physicalDevice->getQueueFamilyProperties();
// get the first index into queueFamilyProperties which supports graphics and compute
auto graphicsAndComputeQueueFamilyProperty =
std::find_if( queueFamilyProperties.begin(),
queueFamilyProperties.end(),
[]( vk::QueueFamilyProperties const & qfp ) { return (qfp.queueFlags & vk::QueueFlagBits::eGraphics && qfp.queueFlags & vk::QueueFlagBits::eCompute); } );
graphicsAndComputeIndex = static_cast<uint32_t>( std::distance( queueFamilyProperties.begin(), graphicsAndComputeQueueFamilyProperty ) );The changed queue family index selection code will now try to find a queue family that supports both graphics and compute.
We can then get a compute queue from this queue family in createLogicalDevice:
computeQueue = std::make_unique<vk::raii::Queue>( *device, graphicsAndComputeIndex, 0 );The compute shader stage
In the graphics samples, we have used different pipeline stages to load shaders and access descriptors.
Compute shaders are accessed in a similar way by using the vk::ShaderStageFlagBits::eCompute pipeline.
So loading a compute shader is just the same as loading a vertex shader, but with a different shader stage.
We’ll talk about this in detail in the next paragraphs.
Compute also introduces a new binding point type for descriptors and pipelines named vk::PipelineBindPoint::eCompute that we’ll have to use later on.
Loading compute shaders
Loading compute shaders in our application is the same as loading any other shader.
The only real difference is that we’ll need to use the vk::ShaderStageFlagBits::eCompute mentioned above.
auto computeShaderCode = readFile("shaders/slang.spv");
vk::PipelineShaderStageCreateInfo computeShaderStageInfo({}, vk::ShaderStageFlagBits::eCompute, shaderModule, "compMain");
...Preparing the shader storage buffers
Earlier on, we learned that we can use shader storage buffers to pass arbitrary data to compute shaders. For this example, we will upload an array of particles to the GPU, so we can manipulate it directly in the GPU’s memory.
In the frames in flight chapter, we talked about duplicating resources per frame in flight, so we can keep the CPU and the GPU busy. First, we declare a vector for the buffer object and the device memory backing it up:
std::vector<vk::raii::Buffer> shaderStorageBuffers;
std::vector<vk::raii::DeviceMemory> shaderStorageBuffersMemory;In the createShaderStorageBuffers we then clear those vectors to clean up
any objects already created in their as is our RAII practice.
shaderStorageBuffers.clear();
shaderStorageBuffersMemory.clear();With this setup in place, we can start to move the initial particle information to the GPU. We first initialize a vector of particles on the host side:
// Initialize particles
std::default_random_engine rndEngine((unsigned)time(nullptr));
std::uniform_real_distribution<float> rndDist(0.0f, 1.0f);
// Initial particle positions on a circle
std::vector<Particle> particles(PARTICLE_COUNT);
for (auto& particle : particles) {
float r = 0.25f * sqrtf(rndDist(rndEngine));
float theta = rndDist(rndEngine) * 2.0f * 3.14159265358979323846f;
float x = r * cosf(theta) * HEIGHT / WIDTH;
float y = r * sinf(theta);
particle.position = glm::vec2(x, y);
particle.velocity = normalize(glm::vec2(x,y)) * 0.00025f;
particle.color = glm::vec4(rndDist(rndEngine), rndDist(rndEngine), rndDist(rndEngine), 1.0f);
}We then create a staging buffer in the host’s memory to hold the initial particle properties:
vk::DeviceSize bufferSize = sizeof(Particle) * PARTICLE_COUNT;
// Create a staging buffer used to upload data to the gpu
vk::raii::Buffer stagingBuffer({});
vk::raii::DeviceMemory stagingBufferMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eTransferSrc, vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent, stagingBuffer, stagingBufferMemory);
void* dataStaging = stagingBufferMemory.mapMemory(0, bufferSize);
memcpy(dataStaging, particles.data(), (size_t)bufferSize);
stagingBufferMemory.unmapMemory();Using this staging buffer as a source, we then create the per-frame shader storage buffers and copy the particle properties from the staging buffer to each of these:
// Copy initial particle data to all storage buffers
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vk::raii::Buffer shaderStorageBufferTemp({});
vk::raii::DeviceMemory shaderStorageBufferTempMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eTransferDst, vk::MemoryPropertyFlagBits::eDeviceLocal, shaderStorageBufferTemp, shaderStorageBufferTempMemory);
copyBuffer(stagingBuffer, shaderStorageBufferTemp, bufferSize);
shaderStorageBuffers.emplace_back(std::move(shaderStorageBufferTemp));
shaderStorageBuffersMemory.emplace_back(std::move(shaderStorageBufferTempMemory));
}
}Descriptors
Setting up descriptors for compute is almost identical to graphics.
The only difference is that descriptors need to have the vk::ShaderStageFlagBits::eCompute set to make them accessible by the compute stage:
std::array layoutBindings{
vk::DescriptorSetLayoutBinding(0, vk::DescriptorType::eUniformBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
};
...Note that you can combine shader stages here, so if you want the descriptor to be accessible from the vertex and compute stage, e.g., for a uniform buffer with parameters shared across them, you set the bits for both stages:
layoutBindings[0].stageFlags = vk::ShaderStageFlagBits::eVertex | vk::ShaderStageFlagBits::eCompute;Here is the descriptor setup for our sample. The layout looks like this:
std::array layoutBindings{
vk::DescriptorSetLayoutBinding(0, vk::DescriptorType::eUniformBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
vk::DescriptorSetLayoutBinding(1, vk::DescriptorType::eStorageBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
vk::DescriptorSetLayoutBinding(2, vk::DescriptorType::eStorageBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr)
};
vk::DescriptorSetLayoutCreateInfo layoutInfo({}, layoutBindings.size(), layoutBindings.data());
computeDescriptorSetLayout = std::make_unique<vk::raii::DescriptorSetLayout>( *device, layoutInfo );Looking at this setup, you might wonder why we have two layout bindings for shader storage buffer objects, even though we’ll only render a single particle system. This is because the particle positions are updated frame by frame based on a delta time. This means that each frame needs to know about the last frames' particle positions, so it can update them with a new delta time and write them to its own SSBO:

For that, the compute shader needs to have access to the last and current frame’s SSBOs.
This is done by passing both to the compute shader in our descriptor setup.
See the storageBufferInfoLastFrame and storageBufferInfoCurrentFrame:
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vk::DescriptorBufferInfo bufferInfo(uniformBuffers[i], 0, sizeof(UniformBufferObject));
vk::DescriptorBufferInfo storageBufferInfoLastFrame(shaderStorageBuffers[(i - 1) % MAX_FRAMES_IN_FLIGHT], 0, sizeof(Particle) * PARTICLE_COUNT);
vk::DescriptorBufferInfo storageBufferInfoCurrentFrame(shaderStorageBuffers[i], 0, sizeof(Particle) * PARTICLE_COUNT);
std::array descriptorWrites{
vk::WriteDescriptorSet( computeDescriptorSets[i], 0, 0, 1, vk::DescriptorType::eUniformBuffer, nullptr, &bufferInfo ),
vk::WriteDescriptorSet( computeDescriptorSets[i], 1, 0, 1, vk::DescriptorType::eStorageBuffer, nullptr, &storageBufferInfoLastFrame),
vk::WriteDescriptorSet( computeDescriptorSets[i], 2, 0, 1, vk::DescriptorType::eStorageBuffer, nullptr, &storageBufferInfoCurrentFrame),
};
device->updateDescriptorSets(descriptorWrites, {});
}Remember that we also have to request the descriptor types for the SSBOs from our descriptor pool:
std::array poolSize {
vk::DescriptorPoolSize( vk::DescriptorType::eUniformBuffer, MAX_FRAMES_IN_FLIGHT),
vk::DescriptorPoolSize( vk::DescriptorType::eStorageBuffer, MAX_FRAMES_IN_FLIGHT * 2)
};We need to double the number of vk::DescriptorType::eStorageBuffer types requested from the pool by two because our sets reference the SSBOs of the last and current frame.
Compute pipelines
As compute is not a part of the graphics pipeline, we can’t use device→createGraphicsPipeline.
Instead, we need to create a dedicated compute pipeline with device→createComputePipeline for running our compute commands.
Since a compute pipeline does not touch any of the rasterization state, it has a lot less state than a graphics pipeline:
vk::PipelineLayoutCreateInfo pipelineLayoutInfo({}, 1, &**computeDescriptorSetLayout);
computePipelineLayout = std::make_unique<vk::raii::PipelineLayout>( *device, pipelineLayoutInfo );The setup is a lot simpler, as we only require one shader stage and a pipeline layout. The pipeline layout works the same as with the graphics pipeline:
vk::ComputePipelineCreateInfo pipelineInfo({}, computeShaderStageInfo, *computePipelineLayout);
computePipeline = std::make_unique<vk::raii::Pipeline>(device->createComputePipeline( nullptr, pipelineInfo));Compute space
Before we get into how a compute shader works and how we submit compute workloads to the GPU, we need to talk about two important compute concepts: work groups and invocations. They define an abstract execution model for how compute workloads are processed by the compute hardware of the GPU in three dimensions (x, y, and z).
Work groups define how the compute workloads are formed and processed by the compute hardware of the GPU. You can think of them as work items the GPU has to work through. Work group dimensions are set by the application at command buffer time using a dispatch command.
And each work group then is a collection of invocations that execute the same compute shader. Invocations can potentially run in parallel, and their dimensions are set in the compute shader. Invocations within a single workgroup have access to shared memory.
This image shows the relation between these two in three dimensions:

The number of dimensions for work groups (defined by computeCommandBuffers[frameIndex]→dispatch) and invocations depends (defined by the local sizes in the compute shader) on how input data is structured.
If you e.g.,
work on a one-dimensional array, like we do in this chapter, you only have to specify the x dimension for both.
As an example: If we dispatch a work group count of [64, 1, 1] with a compute shader local size of [32, 32, 1], our compute shader will be invoked 64 x 32 x 32 = 65,536 times.
Note that the maximum count for work groups and local sizes differs from implementation to implementation, so you should always check the compute related maxComputeWorkGroupCount, maxComputeWorkGroupInvocations and maxComputeWorkGroupSize limits in VkPhysicalDeviceLimits.
Compute shaders
Now that we have learned about all the parts required to set up a compute shader pipeline, it’s time to take a look at compute shaders. All the things we learned about using GLSL shaders, e.g., for vertex and fragment shaders also apply to compute shaders. The syntax is the same, and many concepts like passing data between the application and the shader are the same. But there are some important differences.
A very basic compute shader for updating a linear array of particles may look like this:
struct Particle {
float2 position;
float2 velocity;
float4 color;
};
struct UniformBuffer {
float deltaTime;
};
ConstantBuffer<UniformBuffer> ubo;
struct ParticleSSBO {
Particle particles;
};
StructuredBuffer<ParticleSSBO> particlesIn;
RWStructuredBuffer<ParticleSSBO> particlesOut;
[shader("compute")]
[numthreads(256,1,1)]
void compMain(uint3 threadId : SV_DispatchThreadID)
{
uint index = threadId.x;
particlesOut[index].particles.position = particlesIn[index].particles.position + particlesIn[index].particles.velocity.xy * ubo.deltaTime;
particlesOut[index].particles.velocity = particlesIn[index].particles.velocity;
// Flip movement at window border
if ((particlesOut[index].particles.position.x <= -1.0) || (particlesOut[index].particles.position.x >= 1.0)) {
particlesOut[index].particles.velocity.x = -particlesOut[index].particles.velocity.x;
}
if ((particlesOut[index].particles.position.y <= -1.0) || (particlesOut[index].particles.position.y >= 1.0)) {
particlesOut[index].particles.velocity.y = -particlesOut[index].particles.velocity.y;
}
}The top part of the shader contains the declarations for the shader’s input. First is a uniform buffer object at binding 0, something we already learned about in this tutorial. Below we declare our Particle structure that matches the declaration in the C++ code. Binding 1 then refers to the shader storage buffer object with the particle data from the last frame (see the descriptor setup). Binding 2 points to the SSBO for the current frame, which is the one we’ll be updating with this shader.
An interesting thing is this compute-only declaration related to the compute space:
[numthreads(256,1,1)]This defines the number of invocations of this compute shader in the current work group.
As noted earlier, this is the local part of the compute space.
As we work on a linear 1D array of particles, we only need to specify a number for x dimension in [numthreads(x,y,z)].
The compMain function then reads from the last frame’s SSBO and writes the
updated particle position to the SSBO for the current frame.
Similar to other shader types, compute shaders have their own set of builtin input variables.
Our passed in ThreadId is a variable that uniquely identifies the current
compute shader invocation
across the current dispatch. It gains that capability by the
SV_DispatchThreadID annotation.
We use this to index into our particle array.
Running compute commands
Dispatch
Now it’s time to actually tell the GPU to do some compute.
This is done by calling computeCommandBuffers[frameIndex]→dispatch inside a command buffer.
While not perfectly true, a dispatch is for compute as a draw call like commandBuffers[frameIndex]→draw is for graphics.
This dispatches a given number of compute work items in at max.
three dimensions.
computeCommandBuffers[frameIndex]->begin({});
...
computeCommandBuffers[frameIndex]->bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
computeCommandBuffers[frameIndex]->bindDescriptorSets(vk::PipelineBindPoint::eCompute, *computePipelineLayout, 0, {computeDescriptorSets[frameIndex]}, {});
computeCommandBuffers[frameIndex]->dispatch( PARTICLE_COUNT / 256, 1, 1 );
...
computeCommandBuffers[frameIndex]->end();The computeCommandBuffers[frameIndex]→dispatch will dispatch PARTICLE_COUNT / 256 local work groups in the x dimension.
As our particle array is linear, we leave the other two dimensions at one, resulting in a one-dimensional dispatch.
But why do we divide the number of particles (in our array) by 256?
That’s because in the previous paragraph, we defined that every compute shader in a work group will do 256 invocations.
So if we were to have 4096 particles, we would dispatch 16 work groups, with each work group running 256 compute shader invocations.
Getting the two numbers right usually takes some tinkering and profiling, depending on your workload and the hardware you’re running on.
If your particle size is dynamic and can’t always be divided by e.g.,
256, you can always use gl_GlobalInvocationID at the start of your compute shader and return from it if the global invocation index is greater than the number of your particles.
And just as was the case for the compute pipeline, a compute command buffer has a lot less state than a graphics command buffer. There’s no need to start a render pass or set a viewport.
Submitting work
As our sample does both compute and graphics operations, we’ll be doing two submits to both the graphics and compute queue per frame (see the drawFrame function):
...
computeQueue->submit(submitInfo, **computeInFlightFences[frameIndex]);
...
graphicsQueue->submit(submitInfo, **inFlightFences[frameIndex]);The first submit to the compute queue updates the particle positions using the compute shader, and the second submit will then use that updated data to draw the particle system.
Synchronizing graphics and compute
Synchronization is an important part of Vulkan, even more so when doing compute in conjunction with graphics. Wrong or lacking synchronization may result in the vertex stage starting to draw (=read) particles while the compute shader hasn’t finished updating (=write) them (read-after-write hazard), or the compute shader could start updating particles that are still in use by the vertex part of the pipeline (write-after-read hazard).
So we must make sure that those cases don’t happen by properly synchronizing the graphics and the compute load. There are different ways of doing so, depending on how you submit your compute workload, but in our case with two separate submits, we’ll be using semaphores and fences to ensure that the vertex shader won’t start fetching vertices until the compute shader has finished updating them.
This is necessary as even though the two submits are ordered one-after-another, there is no guarantee that they execute on the GPU in this order. Adding in wait and signal semaphores ensures this execution order.
So we first add a new set of synchronization primitives for the compute work in createSyncObjects.
The compute fences, just like the graphics fences, are created in the
signaled state because otherwise, the first draw would time out while waiting
for the fences to be signaled as detailed
here:
std::vector<std::unique_ptr<vk::raii::Fence>> computeInFlightFences;
std::vector<std::unique_ptr<vk::raii::Semaphore>> computeFinishedSemaphores;
...
computeInFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
computeFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
...
computeFinishedSemaphores[i] = std::make_unique<vk::raii::Semaphore>(*device, vk::SemaphoreCreateInfo());
computeInFlightFences[i] = std::make_unique<vk::raii::Fence>(*device, vk::FenceCreateInfo(vk::FenceCreateFlagBits::eSignaled));
}We then use these to synchronize the compute buffer submission with the graphics submission:
{
// Compute submission
while ( vk::Result::eTimeout == device->waitForFences(**computeInFlightFences[frameIndex], vk::True, UINT64_MAX) )
;
updateUniformBuffer(frameIndex);
device->resetFences( **computeInFlightFences[frameIndex] );
computeCommandBuffers[frameIndex]->reset();
recordComputeCommandBuffer();
const vk::SubmitInfo submitInfo({}, {}, {**computeCommandBuffers[frameIndex]}, { **computeFinishedSemaphores[frameIndex]});
computeQueue->submit(submitInfo, **computeInFlightFences[frameIndex]);
}
{
// Graphics submission
while ( vk::Result::eTimeout == device->waitForFences(**inFlightFences[frameIndex], vk::True, UINT64_MAX))
...
device->resetFences( **inFlightFences[frameIndex] );
commandBuffers[frameIndex]->reset();
recordCommandBuffer(imageIndex);
vk::Semaphore waitSemaphores[] = {**presentCompleteSemaphore[frameIndex], **computeFinishedSemaphores[frameIndex]};
vk::PipelineStageFlags waitDestinationStageMask[] = { vk::PipelineStageFlagBits::eVertexInput, vk::PipelineStageFlagBits::eColorAttachmentOutput };
const vk::SubmitInfo submitInfo( waitSemaphores, waitDestinationStageMask, {**commandBuffers[frameIndex]}, {**renderFinishedSemaphore[frameIndex]} );
graphicsQueue->submit(submitInfo, **inFlightFences[frameIndex]);Similar to the sample in the
semaphore chapter, this setup will immediately run the
compute shader as we haven’t specified any wait semaphores.
Note that we’re using scoping braces above to ensure that the RAII temporary
variables we use get a chance to clean themselves up between the compute and
the graphics stage.
This is fine, as we are waiting for the compute command buffer of the current frame to finish execution before the compute submission with the device→waitForFences command.
The graphics submission, on the other hand, needs to wait for the compute work to finish so it doesn’t start fetching vertices while the compute buffer is still updating them.
So we wait on the computeFinishedSemaphores for the current frame and have the graphics submission wait on the vk::PipelineStageFlagBits::eVertexInput stage, where vertices are consumed.
But it also needs to wait for presentation, so the fragment shader won’t output to the color attachments until the image has been presented.
So we also wait on the imageAvailableSemaphores on the current frame at the vk::PipelineStageFlagBits::eColorAttachmentOutput stage.
Timeline semaphores: An improved synchronization mechanism
The synchronization approach described above uses binary semaphores, which have a simple signaled/unsignaled state. While this works well for many scenarios, Vulkan also offers a more powerful synchronization primitive: timeline semaphores.
Timeline semaphores were introduced as an extension and later promoted to core in Vulkan 1.2. Unlike binary semaphores, timeline semaphores have a 64-bit unsigned integer counter value that can be waited on and signaled to specific values. This provides several advantages over binary semaphores:
-
Reusability: A single timeline semaphore can be used for multiple synchronization points, reducing the number of semaphores needed.
-
Host synchronization: Timeline semaphores can be signaled and waited on from the host (CPU) without submitting commands to a queue.
-
Out-of-order signaling: You can signal a timeline semaphore to a value higher than what’s currently being waited on, allowing for more flexible synchronization patterns.
-
Multiple pending signals: Unlike binary semaphores, which can only be pending-signaled once, timeline semaphores can have multiple pending signals.
Let’s see how we can modify our particle system example to use timeline semaphores instead of binary semaphores:
First, we need to enable the timeline semaphore feature when creating the logical device:
vk::PhysicalDeviceTimelineSemaphoreFeaturesKHR timelineSemaphoreFeatures;
timelineSemaphoreFeatures.timelineSemaphore = vk::True;
// Chain this to your device creation infoInstead of creating multiple binary semaphores, we create a single timeline semaphore:
vk::SemaphoreTypeCreateInfo semaphoreType{ .semaphoreType = vk::SemaphoreType::eTimeline, .initialValue = 0 };
semaphore = vk::raii::Semaphore(device, {.pNext = &semaphoreType});
timelineValue = 0;In our draw frame function, we use incrementing timeline values to coordinate work between compute and graphics:
// Update timeline value for this frame
uint64_t computeWaitValue = timelineValue;
uint64_t computeSignalValue = ++timelineValue;
uint64_t graphicsWaitValue = computeSignalValue;
uint64_t graphicsSignalValue = ++timelineValue;For the compute submission, we use a timeline semaphore submit info structure:
vk::TimelineSemaphoreSubmitInfo computeTimelineInfo{
.waitSemaphoreValueCount = 1,
.pWaitSemaphoreValues = &computeWaitValue,
.signalSemaphoreValueCount = 1,
.pSignalSemaphoreValues = &computeSignalValue
};
vk::PipelineStageFlags waitStages[] = {vk::PipelineStageFlagBits::eComputeShader};
vk::SubmitInfo computeSubmitInfo{
.pNext = &computeTimelineInfo,
.waitSemaphoreCount = 1,
.pWaitSemaphores = &*semaphore,
.pWaitDstStageMask = waitStages,
.commandBufferCount = 1,
.pCommandBuffers = &*computeCommandBuffers[frameIndex],
.signalSemaphoreCount = 1,
.pSignalSemaphores = &*semaphore
};
computeQueue.submit(computeSubmitInfo, nullptr);Similarly, for the graphics submission:
vk::PipelineStageFlags waitStage = vk::PipelineStageFlagBits::eVertexInput;
vk::TimelineSemaphoreSubmitInfo graphicsTimelineInfo{
.waitSemaphoreValueCount = 1,
.pWaitSemaphoreValues = &graphicsWaitValue,
.signalSemaphoreValueCount = 1,
.pSignalSemaphoreValues = &graphicsSignalValue
};
vk::SubmitInfo graphicsSubmitInfo{
.pNext = &graphicsTimelineInfo,
.waitSemaphoreCount = 1,
.pWaitSemaphores = &*semaphore,
.pWaitDstStageMask = &waitStage,
.commandBufferCount = 1,
.pCommandBuffers = &*commandBuffers[frameIndex],
.signalSemaphoreCount = 1,
.pSignalSemaphores = &*semaphore
};
graphicsQueue.submit(graphicsSubmitInfo, nullptr);Before presenting, we wait for the graphics work to complete:
vk::SemaphoreWaitInfo waitInfo{
.semaphoreCount = 1,
.pSemaphores = &*semaphore,
.pValues = &graphicsSignalValue
};
// Wait for graphics to complete before presenting
auto result = device.waitSemaphores(waitInfo, UINT64_MAX);
if (result != vk::Result::eSuccess)
{
throw std::runtime_error("failed to wait for semaphore!");
}
vk::PresentInfoKHR presentInfo{
.waitSemaphoreCount = 0, // No binary semaphores needed
.pWaitSemaphores = nullptr,
.swapchainCount = 1,
.pSwapchains = &*swapChain,
.pImageIndices = &imageIndex
};This timeline semaphore approach offers several benefits over the binary semaphore implementation:
-
Simplified resource management: We only need a single semaphore instead of multiple semaphores per frame in flight.
-
More explicit synchronization: The timeline values make it clear which operations depend on each other.
-
Reduced overhead: With fewer synchronization objects, there’s less overhead in managing them.
-
More flexible synchronization patterns: Timeline semaphores enable more complex synchronization scenarios that would be difficult with binary semaphores.
Timeline semaphores are particularly useful in scenarios with multiple dependent operations, like our compute-then-graphics workflow, or when you need to synchronize between the host and device. They provide a more powerful and flexible synchronization mechanism that can simplify your code while enabling more complex synchronization patterns.
Drawing the particle system
Earlier on, we learned that buffers in Vulkan can have multiple use-cases, and so we created the shader storage buffer that contains our particles with both the shader storage buffer bit and the vertex buffer bit. This means that we can use the shader storage buffer for drawing just as we used "pure" vertex buffers in the previous chapters.
We first set up the vertex input state to match our particle structure:
struct Particle {
...
static std::array<vk::VertexInputAttributeDescription, 2> getAttributeDescriptions() {
return {
vk::VertexInputAttributeDescription( 0, 0, vk::Format::eR32G32Sfloat, offsetof(Particle, position) ),
vk::VertexInputAttributeDescription( 1, 0, vk::Format::eR32G32B32A32Sfloat, offsetof(Particle, color) ),
};
}
};Note that we don’t add velocity to the vertex input attributes, as this is only used by the compute shader.
We then bind and draw it like we would with any vertex buffer:
commandBuffers[frameIndex]->bindVertexBuffers(0, { *shaderStorageBuffers[frameIndex] }, {0});
commandBuffers[frameIndex]->draw( PARTICLE_COUNT, 1, 0, 0 );Conclusion
In this chapter, we learned how to use compute shaders to offload work from the CPU to the GPU. Without compute shaders, many effects in modern games and applications would either not be possible or would run a lot slower. But even more than graphics, compute has a lot of use-cases, and this chapter only gives you a glimpse of what’s possible. So now that you know how to use compute shaders, you may want to take a look at some advanced compute topics like:
-
Shared memory
-
Atomic operations
You can find some advanced compute samples in the official Khronos Vulkan Samples repository.