Subpasses
| The source for this sample can be found in the Khronos Vulkan samples github repository. |
Overview
Vulkan introduces the concept of subpasses to subdivide a single render pass into separate logical phases. The benefit of using subpasses over multiple render passes is that a GPU is able to perform various optimizations. Tile-based renderers, for example, can take advantage of tile memory, which being on chip is decisively faster than external memory, potentially saving a considerable amount of bandwidth.
Deferred rendering
The Subpasses sample implements a deferred renderer, which splits rendering in two passes:
-
A geometry pass, where data needed for shading is written to the G-buffer (depth, albedo, normals).
-
A lighting pass, where shading is performed using the information in the G-buffer.
The G-buffer layout used by the sample is below a limit of 128-bit per pixel of tile buffer color storage (more about that in the next section):
-
Lighting (
RGBA8_SRGB), as attachment #0 will take advantage of transaction elimination. -
Depth (
D32_SFLOAT), which does not add up to the 128-bit limit. -
Albedo (
RGBA8_UNORM) -
Normal (
RGB10A2_UNORM)
By using the format RGB10A2_UNORM for the normal buffer, normal values, which are within [-1,1], need to be transformed into [0,1].
The formula used in the shader is this:
out_normal = 0.5 * in_normal + 0.5;Position can be reconstructed from the lighting pass using the depth attachment, using the following technique: [1]
mat4 inv_view_proj = inverse(projection * view);
vec2 inv_resolution = vec2(1.0f / width, 1.0f / height);
// Load depth from tile buffer and reconstruct world position
vec4 clip = vec4(in_uv * 2.0 - 1.0,
subpassLoad(i_depth).x, 1.0);
vec4 world_w = inv_view_proj * clip;
vec3 world = world_w.xyz / world_w.w;In order to highlight the benefit of subpasses over multiple render passes, the sample allows the user to switch between two different techniques at run-time.
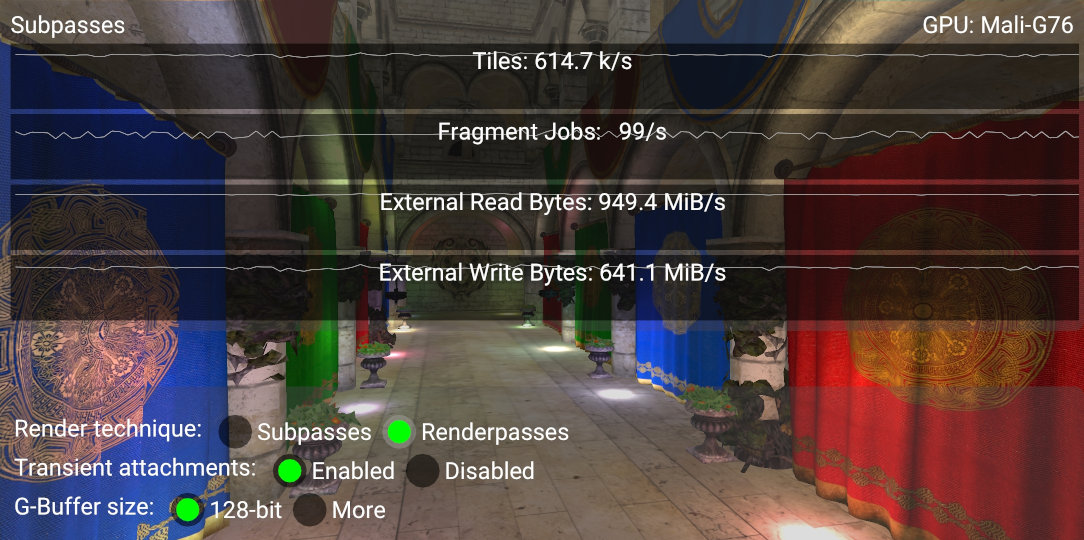
One of the techniques uses two render passes, running one after another.
The first render pass generates the G-buffer, and the second uses it in the lighting stage to generate our final image.
The above screenshot shows four GPU counters (collected by HWCPipe), and their values when using two render passes.
We can see that there is a high number of physical tiles (PTILES) used and a considerable amount of bandwidth (external reads/writes).
Another technique uses a single render pass which is composed of two subpasses. The first subpass generates the G-buffer and the second performs the lighting calculations to generate our final image (similarly to the two render pass technique). On tile-based GPUs the G-buffer might be kept in tile memory across subpasses, which is why this method is considered a best practice.
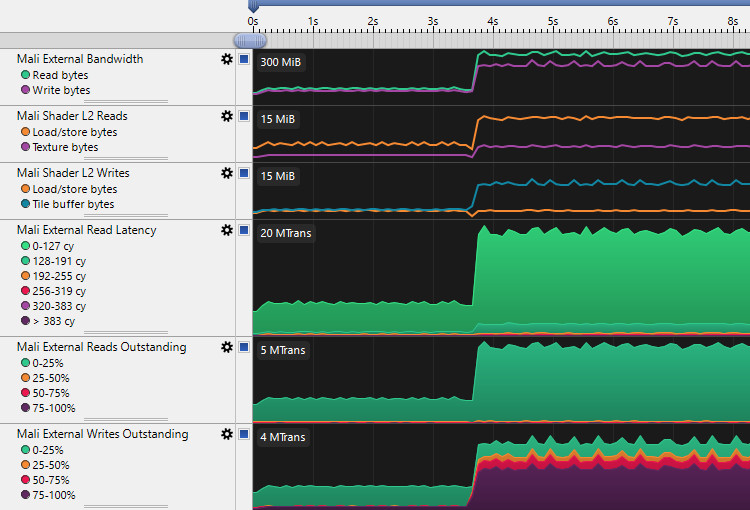
The first thing that you may notice from the Streamline screenshot below is the difference in terms of bandwidth between the two techniques:
-
On the left, from
0sto3.6s, the benefit of the subpasses technique is clear, as it is able to store the G-buffer on tile memory. -
On the right, from
3.7s, is highlighted the two render passes technique, which writes lots of data back to the external memory, as the first render pass needs to store the G-buffer in order to be read by the second render pass.
Merging
As stated by the Vulkan reference, Subpasses with simple framebuffer-space dependencies may be merged into a single tile rendering pass, keeping the attachment data on-chip for the duration of a renderpass. [2].
Since subpass information is known ahead of time, the driver is able to detect if two or more subpasses can be merged together.
The consequence of this is that vkCmdNextSubpass becomes a NOP.
In other words, a GPU driver can optimize even more by merging two or more subpasses together as long as certain requirements are met. Such requirements may vary between vendors, the following are the ones for Arm GPUs:
-
If merge can save a write-out/read-back; two unrelated subpasses which don’t share any data do not benefit from multipass and will not be merged.
-
If the number of unique
VkAttachmentsused for input and color attachments in all considered subpasses is <= 8. Note that depth/stencil does not count towards this limit. -
The depth/stencil attachment does not change between subpasses.
-
Multisample counts are the same for all attachments.
On Mali devices in order to be merged, subpasses are required to use at most 128-bit per pixel of tile buffer color storage, although some of the more recent GPUs such as Mali-G72 increase this to up to 256-bits per pixel. G-buffers requiring more color storage than this can be used at the expense of needing smaller tiles during fragment shading, which can reduce overall throughput and increase bandwidth reading tile lists.
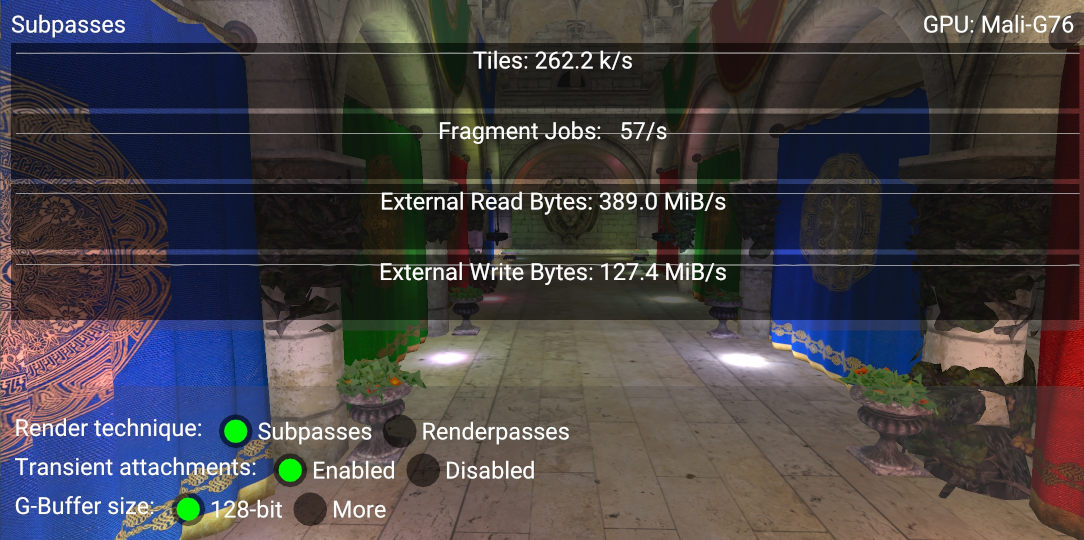
The best way to verify whether two subpasses are merged or not is to compare the physical tiles (PTILES) counter by switching between the subpasses and the render passes techniques.
When we compare the screenshots of the two render techniques on a Mali-G76, we can see that there is approximately a 55% reduction in the number of tiles used (262.2k/s vs 614.7k/s), and therefore a 55% reduction in bandwidth.
In order to calculate the number in the physical tiles counter, you need to know the resolution of the device you are using and the size of a single tile.
In the case of an S10 Mali-G76, the resolution is 2220 * 1080 and a tile is 16x16 pixels.
Therefore every frame needs (2220 * 1080) / (16 * 16) = ~9k tiles.
To get the tiles every second, we multiply this number by the FPS (this can vary) so 9k * 30 = 270k/s which is approximately what we see in the tiles counter.
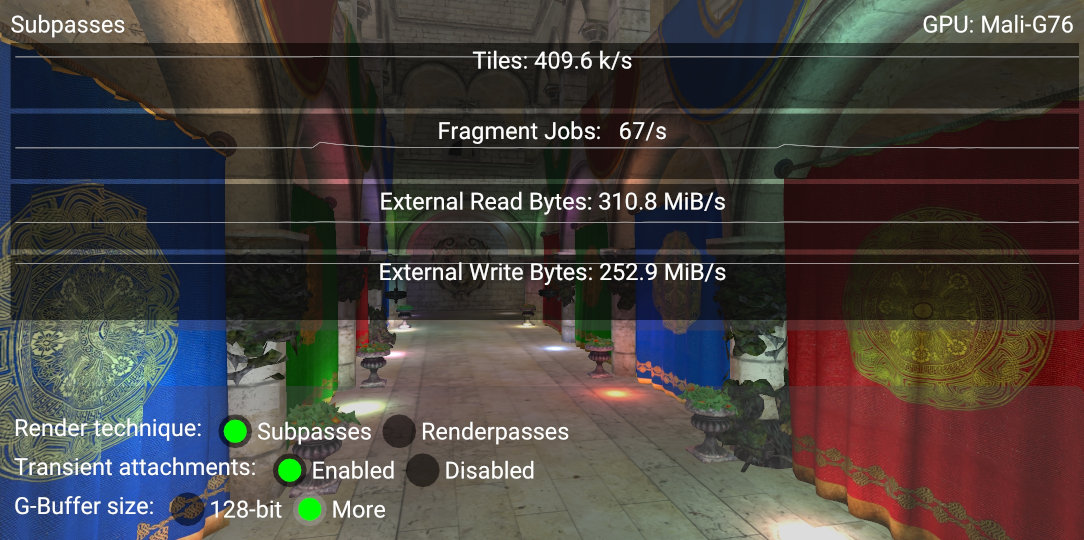
It is important to note that by using a VkImageFormat that requires more bits, it is most likely that the G-buffer will no longer fit the drivers budget, denying the possibility to merge the subpasses.
The following picture shows how the number of physical tiles used almost doubles to 409.6k/s, indicating that subpasses are not merged.
Transient attachments
Some framebuffer attachments in the sample (such as depth, albedo, and normal), are cleared at the beginning of the render pass, written by the geometry subpass, read by the lighting subpass, and discarded at the end of the render pass. If the GPU has enough memory available to store them on tile memory, there is no need to write them back to external memory. Actually, there is not even a need to allocate them at all.

In practice, their image usage needs to be specified as TRANSIENT and their memory needs to be LAZILY_ALLOCATED.
Failing to set these flags properly will lead to an increase of fragment jobs as the GPU will need to write them back to external memory.
As you can see in the above screenshot, we see roughly a double in fragment jobs per second (from 56/s to 113/s).
Further reading
-
Vulkan Multipass at GDC 2017 - community.arm.com
-
Deferring shading with Multipass - arm-software.github.io
-
Vulkan input attachments and subpasses - saschawillems.de
References
-
Getting World Position from Depth Buffer Value - stackoverflow.com
-
Render Pass - vulkan.lunarg.com
Best-practice summary
Do
-
Use subpasses.
-
Keep your G-buffer budget for color small.
-
Use
DEPTH_STENCIL_READ_ONLYimage layout for depth after the geometry pass is done. -
Use
LAZILY_ALLOCATEDmemory to back images for every attachment except for the light buffer, which is the only texture written out to memory. -
Follow the basic render pass best practices, with
LOAD_OP_CLEARorLOAD_OP_DONT_CAREfor attachment loads andSTORE_OP_DONT_CAREfor transient stores.
Don’t
-
Store G-buffer data out to memory.
Impact
-
Not using multipass correctly may force the driver to use multiple physical passes, sending intermediate image data back via main memory between passes. This loses all benefits of the multipass rendering feature.
Debugging
-
The GPU performance counters provide information about the number of physical tiles rendered, which can be used to determine if passes are being merged.
-
The GPU performance counters provide information about the number of fragment threads using late-zs testing, a high value here can be indicative of failing to use
DEPTH_STENCIL_READ_ONLYcorrectly.