Appropriate use of render pass attachments
| The source for this sample can be found in the Khronos Vulkan samples github repository. |
Overview
Vulkan render-passes use attachments to describe input and output render targets. This sample shows how loading and storing attachments might affect performance on mobile.
During the creation of a render-pass, you can specify various color attachments and a depth-stencil attachment.
Each of those is described by a VkAttachmentDescription struct, which contains attributes to specify the load operation (loadOp) and the store operation (storeOp).
This sample lets you choose between different combinations of these operations at runtime.
VkAttachmentDescription desc = {};
desc.loadOp = VK_ATTACHMENT_LOAD_OP_*;
desc.storeOp = VK_ATTACHMENT_STORE_OP_*;Color attachment load operation
The sample renders a scene with a render-pass using one color attachment, which is a swapchain image used for presentation.
Since we do not need to read its content at the beginning of the pass, it would make sense to use LOAD_OP_DONT_CARE in order to avoid spending time loading it.
If we do not draw on the entire framebuffer, the frame might show random colors on the areas we do not draw on.
In addition, it would show pixels drawn during previous frames.
The solution consists in using LOAD_OP_CLEAR to clear the content of the framebuffer using a user-specified color.
VkAttachmentDescription color_desc = {};
color_desc.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
// Remember to set the clear value when beginning the render pass
VkClearValue clear = {};
clear.color = {0.5f, 0.5f, 0.5f, 1.0f};
VkRenderPassBeginInfo begin = {};
begin.clearValueCount = 1;
begin.pClearValues = &clear;Using the LOAD_OP_LOAD flag is the wrong choice in this case.
Not only do we not use its content during this render-pass, it will cost us more in terms of bandwidth.
Below is a screenshot showing a scene rendered using LOAD_OP_LOAD:
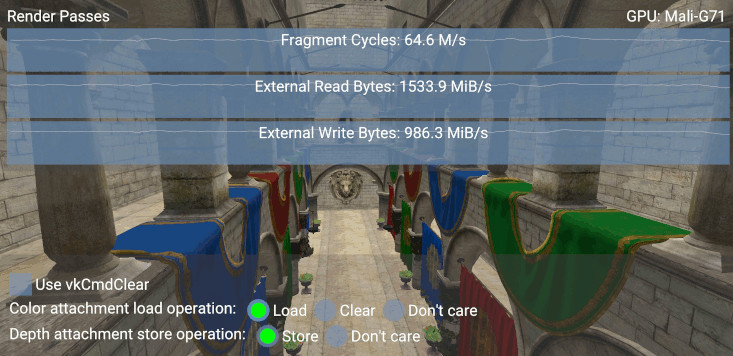
Comparing the read bandwidth values (External Read Bytes graph), we observe a difference of 1533.9 - 933.7 = 600.2 MiB/s if we select LOAD_OP_CLEAR
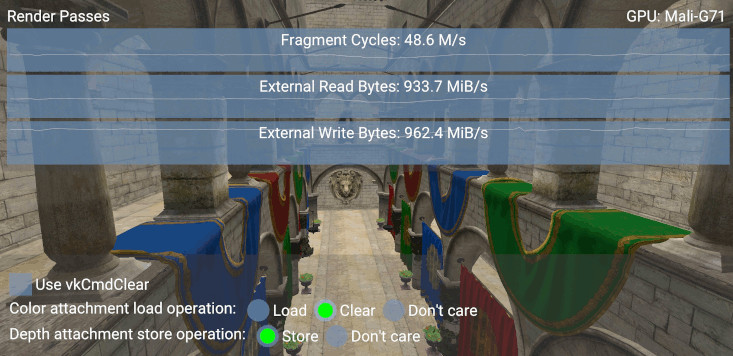
We can estimate the bandwidth cost of loading/storing an uncompressed attachment as width * height * bpp/8 * FPS [MiB/s].
We calculate an estimate of 2220 * 1080 * (32/8) * ~60 = ~575 MiB/s.
The savings will be lower if the images are compressed, see Enabling AFBC in your Vulkan Application.
Depth attachment store operation
The render-pass also uses a depth attachment.
In case we need to use it in a second render-pass, the right operation to set would be STORE_OP_STORE, because choosing STORE_OP_DONT_CARE means that the second render-pass will potentially load the wrong values.
The sample does not have a second render-pass, therefore there is no need to store the depth attachment.
VkAttachmentDescription depth_desc = {};
depth_desc.storeOp = VK_ATTACHMENT_STORE_OP_DONT_CARE;It is worth noticing that we can create a depth image with the LAZILY_ALLOCATED memory property, which means that it will be allocated by tile-based GPUs only if it is actually stored (by using STORE_OP_STORE).
VmaAllocationCreateInfo depth_alloc = {};
depth_alloc.preferredFlags = VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT;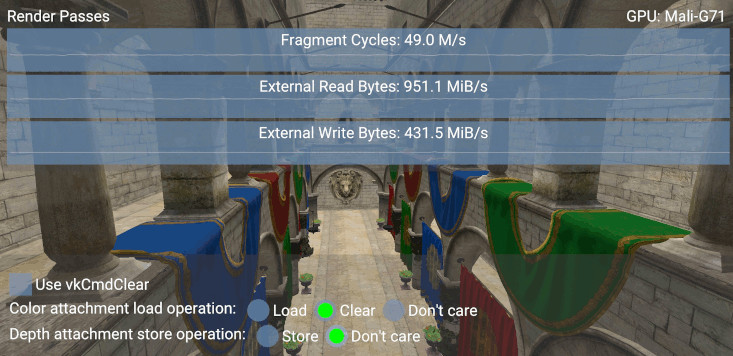
In this case the write transactions were reduced by 986.3 - 431.5 = 554.8 MiB/s, again what we would roughly expect from storing the size of an uncompressed image at ~60 FPS.
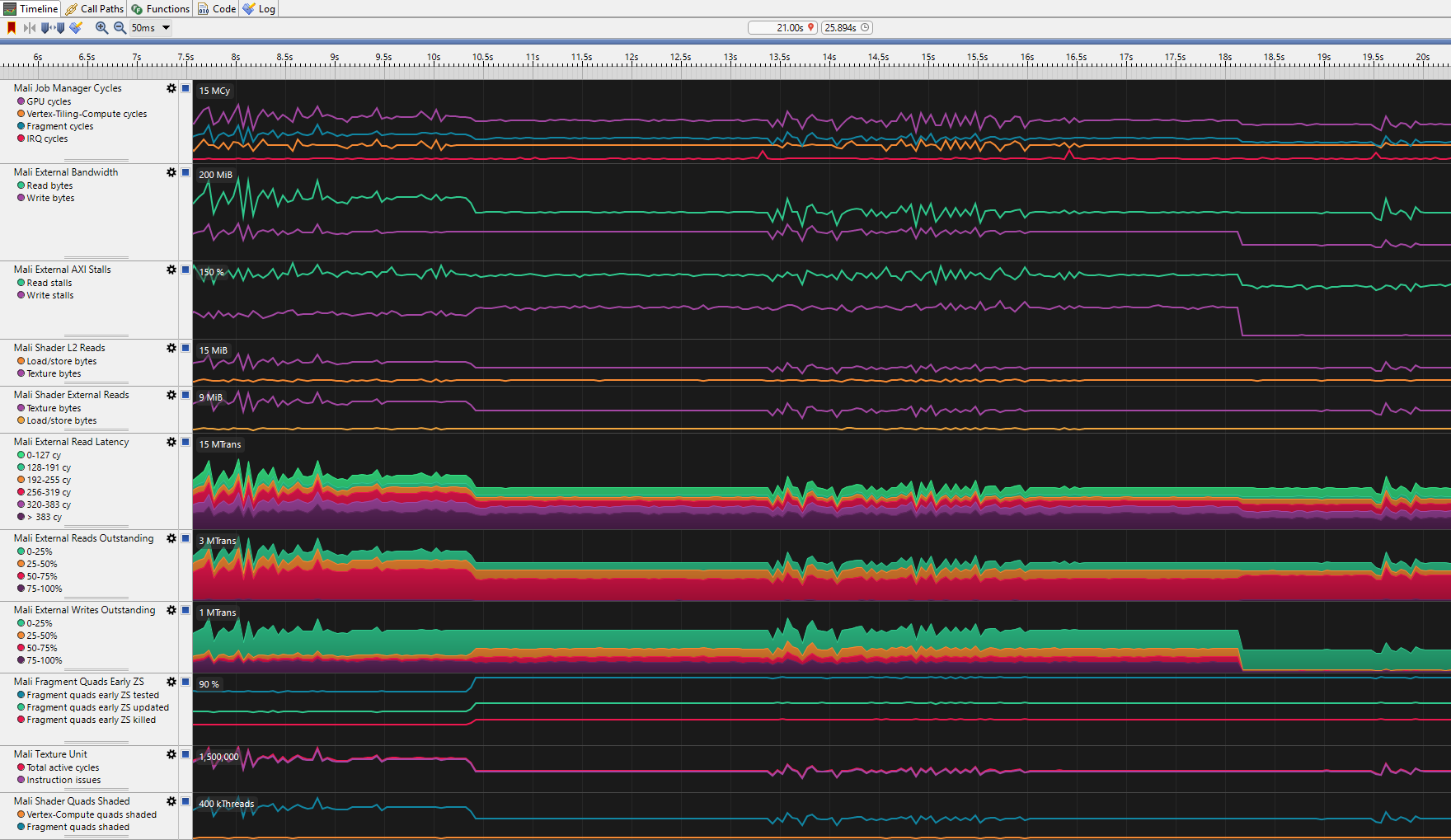
The streamline trace shows us a more in-depth analysis of what is going on in the GPU.
The delta between LOAD_OP_LOAD and LOAD_OP_CLEAR is evident at 10.4s having consistently less external reads.
The delta between STORE_OP_STORE and STORE_OP_DONT_CARE is clear at 18.1s with the external write graphs plunging down.
vkCmdClear* functions
Using the vkCmdClear* to clear the attachments is not needed as you can get the same result by using LOAD_OP_CLEAR.
The following screenshot shows that by using that command the GPU will need ~6 million more fragment cycles per second.
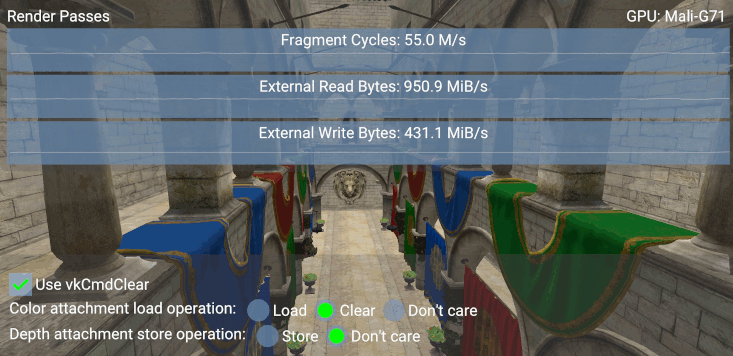
While the vkCmdClear* functions can be used to clear images explicitly, on certain mobile devices this will result in a per-fragment clear shader which results in the additional workload demonstrated in the above screenshot.
Despite this, the vkCmdClear* functions do have uses which are not covered by the loadOp operations, for example the vkCmdClearAttachments function can be used to clear a specific region within an attachment during a render pass.
Depth image usage
Beyond setting the depth image usage bit to specify that it can be used as a DEPTH_STENCIL_ATTACHMENT, we can set the TRANSIENT_ATTACHMENT bit to tell the GPU that it can be used as a transient attachment which will only live for the duration of a single render-pass.
Then if this is backed by LAZILY_ALLOCATED memory it will not even need physical storage.
VkImageCreateInfo depth_info = {VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO};
depth_info.usage = VK_IMAGE_USAGE_TRANSIENT_ATTACHMENT_BIT;Render area granularity
The render area provided to the render pass begin info struct should be tested against the vkGetRenderAreaGranularity to confirm that it is an optimal size.
A render area is optimal when it satisfies all of the following conditions:
-
The
offset.xmember inrenderAreais a multiple of the width member of the horizontal granularity. -
The
offset.ymember inrenderAreais a multiple of the height of the vertical granularity. -
Either the
extent.widthmember inrenderAreais a multiple of the horizontal granularity oroffset.x+extent.widthis equal to the width of the framebuffer in theVkRenderPassBeginInfo. -
Either the
extent.heightmember inrenderAreais a multiple of the vertical granularity oroffset.y+extent.heightis equal to the height of the framebuffer in theVkRenderPassBeginInfo.
Best-practice summary
Do
-
Clear or invalidate each attachment at the start of a render pass using
loadOp = LOAD_OP_CLEARorloadOp = LOAD_OP_DONT_CARE. -
Ensure that color/depth/stencil writes are not masked when clearing; you must clear the entire content of an attachment to get a fast clear of the tile memory.
-
Set the
VK_ATTACHMENT_LOAD_OP_DONT_CAREflag to attachments not used as input for the render-pass. -
Set up any attachment which is only live for the duration of a single render pass as a
TRANSIENT_ATTACHMENTbacked byLAZILY_ALLOCATEDmemory and ensure that the contents are invalidated at the end of the render pass usingstoreOp = STORE_OP_DONT_CARE. -
If you know you are rendering to a sub-region of framebuffer use a scissor box to restrict the area of clearing and rendering required.
Don’t
-
Use
vkCmdClearColorImage()orvkCmdClearDepthStencilImage()for any image which is used inside a render pass later; move the clear to the render passloadOpsetting. -
Use
vkCmdClearAttachments()inside a render pass when not needed as this is not free, unlike a clear or invalidate load operation. -
Clear a render pass by manually writing a constant color using a shader program.
-
Use
loadOp = LOAD_OP_LOADunless your algorithm actually relies on the initial framebuffer state. -
Set
loadOporstoreOpfor attachments which are not actually needed in the render pass; you’ll generate a needless round-trip via tile-memory for that attachment. -
Use
vkCmdBlitImageas a way of upscaling a low-resolution game frame to native resolution if you will render UI/HUD directly on top of it withloadOp = LOAD_OP_LOAD; this will be an unnecessary round-trip to memory.
Impact
-
Correct handling of render passes is critical; failing to follow this advice can result in significantly lower fragment shading performance and increased memory bandwidth due to the need to read non-cleared attachments into the tile memory at the start of rendering and write out non-invalidated attachments at the end of rendering.
Debugging
-
Review API usage of attachments description.
-
Review API usage of render pass creation, and any use of
vkCmdClearColorImage(),vkCmdClearDepthStencilImage()andvkCmdClearAttachments().